Our research
The long-term goals of our research are to advance intelligent autonomous systems by integrating reinforcement learning, modern control theory, and game-theoretic approaches for trustworthy human-robot collaboration. Our research centers on developing advanced control strategies for micro-mobility robots—including wheeled, humanoid, and quadrupedal platforms—to enhance their agility and manipulation in complex environments. We also explore multi-robot coordination and swarm intelligence to enable seamless teamwork among robot fleets. Additionally, we work on safe and energy-efficient control methods for connected and autonomous vehicles to promote sustainable urban mobility in large scale. Leveraging diverse robotic platforms and experimental facilities, ETAIC bridges cutting-edge theory with real-world applications to create intelligent agents capable of complex tasks.

Multi-Agent Safe Decision Making

Trustworthy AI Partner

Contact-Rich Locomotion Control
We work with diverse robotic systems, drawn to the balance between theory and real-world challenges: as models improve, new complexities arise… revealing exciting opportunities… The lab leader blends industry experience with academic rigor, placing our work at the forefront of embodied AI and micro-mobility research.
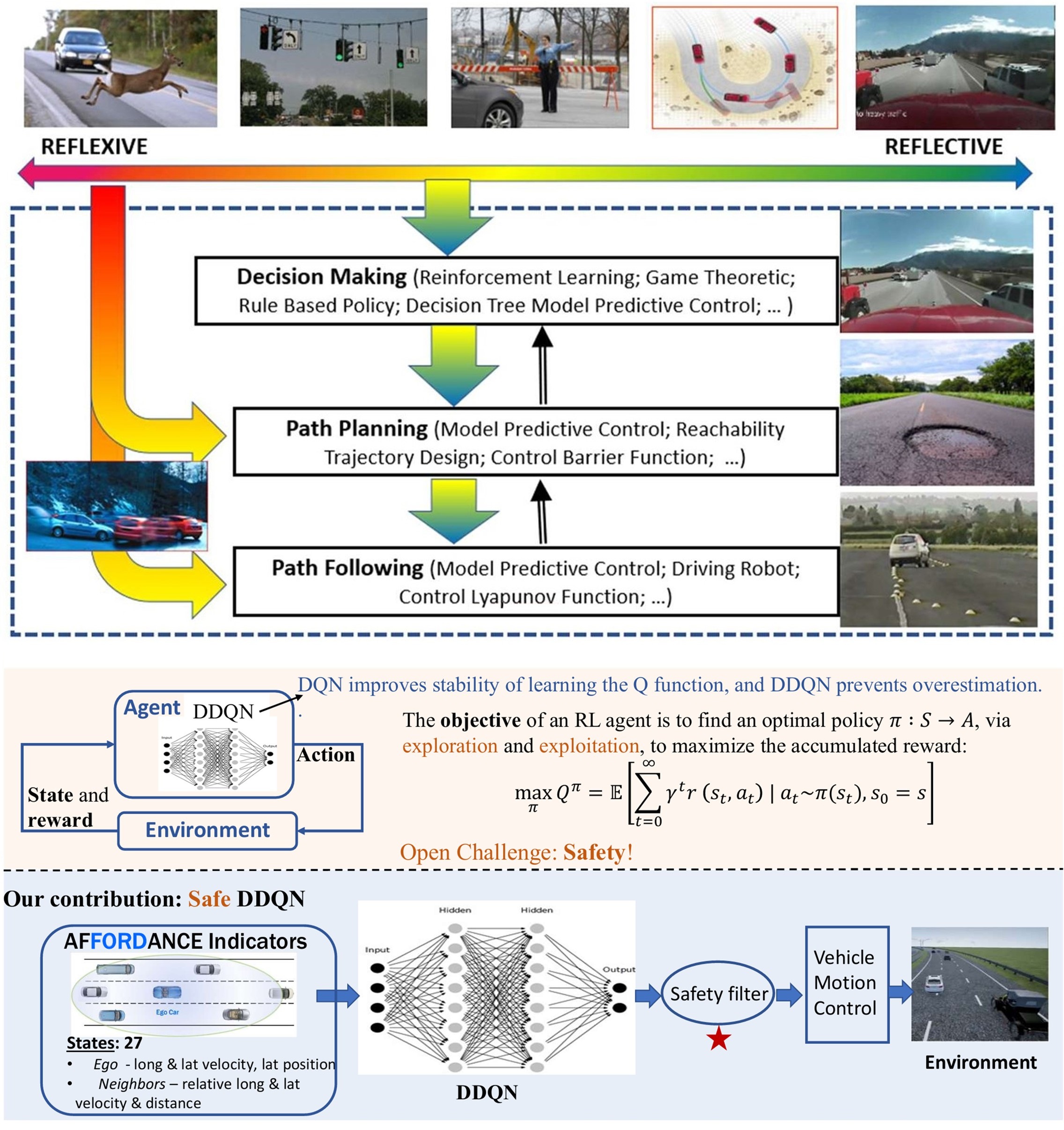
Safe Decision-Making and Control for CAVs in Interactive and Adverse Environments
Our research addressed the core challenges in automated driving, including long-tail road scenarios, dynamic interactions with human agents, and reliable system validation. We explore the intersection of model-based control and data-driven intelligence to build resilient and adaptive autonomous vehicles.
Key Challenges:
- Long-Tail Distribution: Rare and unpredictable events in complex or adverse driving environments.
- Interactive Environments: Safe negotiation with human drivers, pedestrians, and cyclists.
- Testing & Validation: Balancing high performance with robustness under real-world uncertainties.
Our Approach:
- Hybrid Intelligence: Integrating structured models with real-world data to improve adaptability and robustness.
- Hierarchical Architecture: Combining strategic planning with reactive control through cognitive and embodied intelligence layers.
- Safety by Design: Embedding multi-layer safety mechanisms to ensure both proactive and reactive hazard mitigation.
Multi-Agent Reinforcement Learning and Human-Robot Collaboration in Robot Systems
We explore how to empower robots with the ability to make robust decisions through learning in uncertain environments, and to achieve efficient, safe, and trustworthy human-robot interaction. This includes how to ensure that robots maintain high performance and safety when facing unknown or abnormal situations, and how to utilize cutting-edge artificial intelligence technologies (such as reinforcement learning and large language models) to facilitate deeper autonomous learning and adaptation in robots, thereby enabling natural coexistence and collaboration with humans, and laying the foundation for future intelligent automation.
Key Challenges:
- Maintaining reliable robot performance and effectively responding to diverse, unforeseen events within dynamic and uncertain environments, including sensor failures and environmental changes.
- Enabling robots to learn optimal policies safely, strictly adhering to protocols and avoiding hazardous actions.
- Facilitating seamless and intuitive collaboration by allowing robots to understand and adapt to human partners’ dynamic behaviors.
Our Approach:
- Developing safe reinforcement learning frameworks to prevent unsafe states during exploration and policy learning, ensuring robust decision-making.
- Enhancing robot decision-making through interpretability and implicit adaptation, leveraging techniques like explainable AI and large language models for generalized behavior across diverse scenarios.
- Modeling robot-human interactions using strategic games to optimize collaborative outcomes and ensure the resilience of cooperative behaviors in dynamic and uncertain environments.
- Employing control theory means to maintain the stability and safety of multi-agent learning and training processes.
