Publications
Recent Work
---------------------------------------------------------------------------------------------------------------Learning Human-Robot Collaboration via Heterogeneous-Agent Lyapunov Policy Optimization
Hao Zhang, Yaru Niu, Yikai Wang, Ding Zhao and H. Eric Tseng
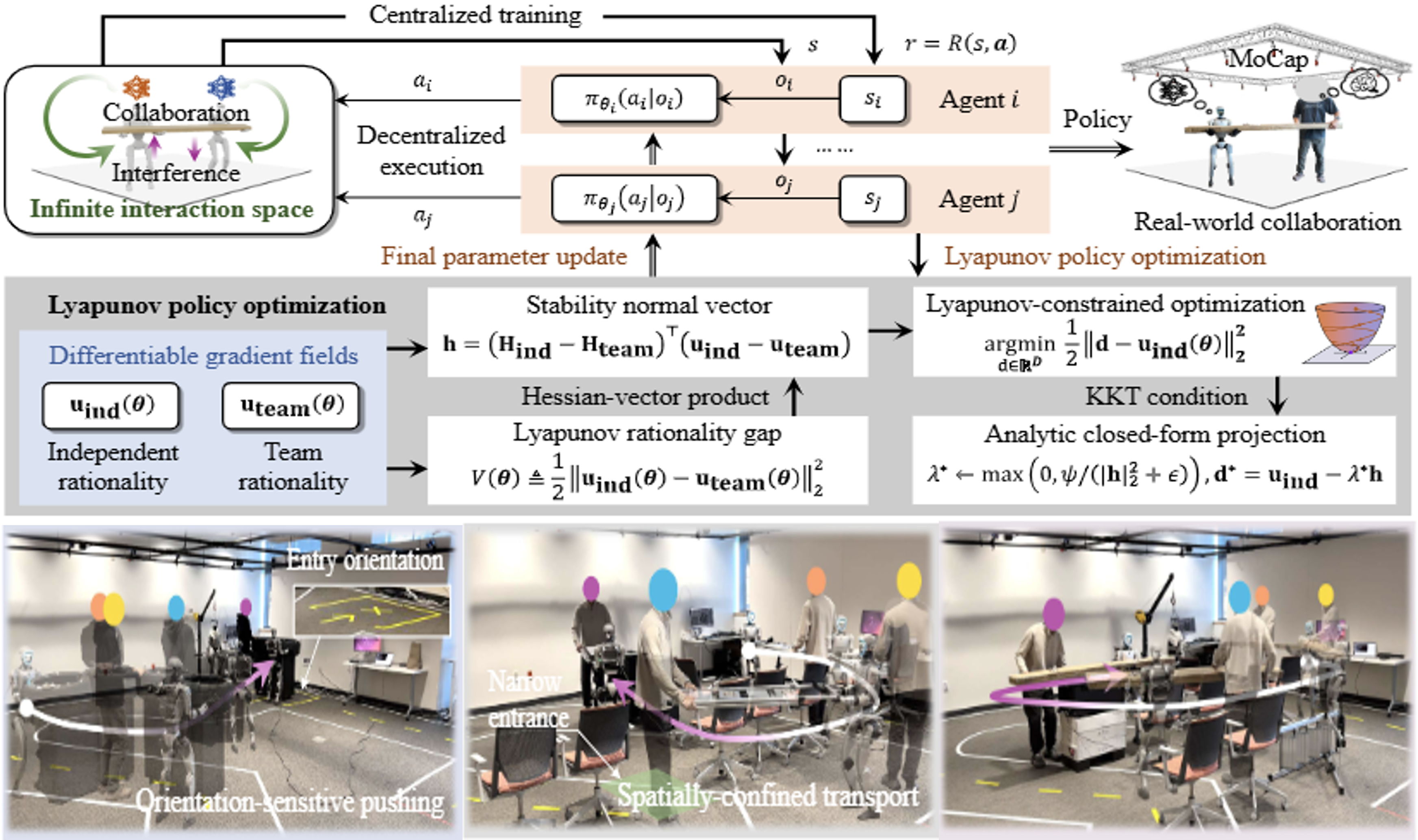
- We propose heterogeneous-agent Lyapunov policy optimization (HALyPO), which establishes formal stability directly in the policy-parameter space by enforcing a per-step Lyapunov decrease condition on a parameter-space disagreement metric.
C2C: A Cognition-to-Control Hierarchy for Human-Robot Collaboration via Multi-Agent Learning
Hao Zhang, Ding Zhao and H. Eric Tseng
- In multi-agent human-robot collaboration, where long-horizon coordination decisions and physical execution must co-evolve under contact, feasibility, and safety constraints. We address this limitation with cognition-to-control (C2C), a three-layer hierarchy that makes the deliberation-to-control pathway explicit.
IO-WBC: Interaction-Orientated Whole-Body Control for Compliant Object Transport
Hao Zhang, Yves Tseng, Ding Zhao and H. Eric Tseng
- We proposed a bio-inspired, interaction-oriented whole-body control (IO-WBC) that functions as an artificial cerebellum - an adaptive motor agent that translates upstream (skill-level) commands into stable, physically consistent whole-body behavior under contact.
Dream to Adapt: Meta Reinforcement Learning by Latent Context Imagination and MDP Imagination
Lu Wen, H. Eric Tseng, Huei Peng, and Songan Zhang
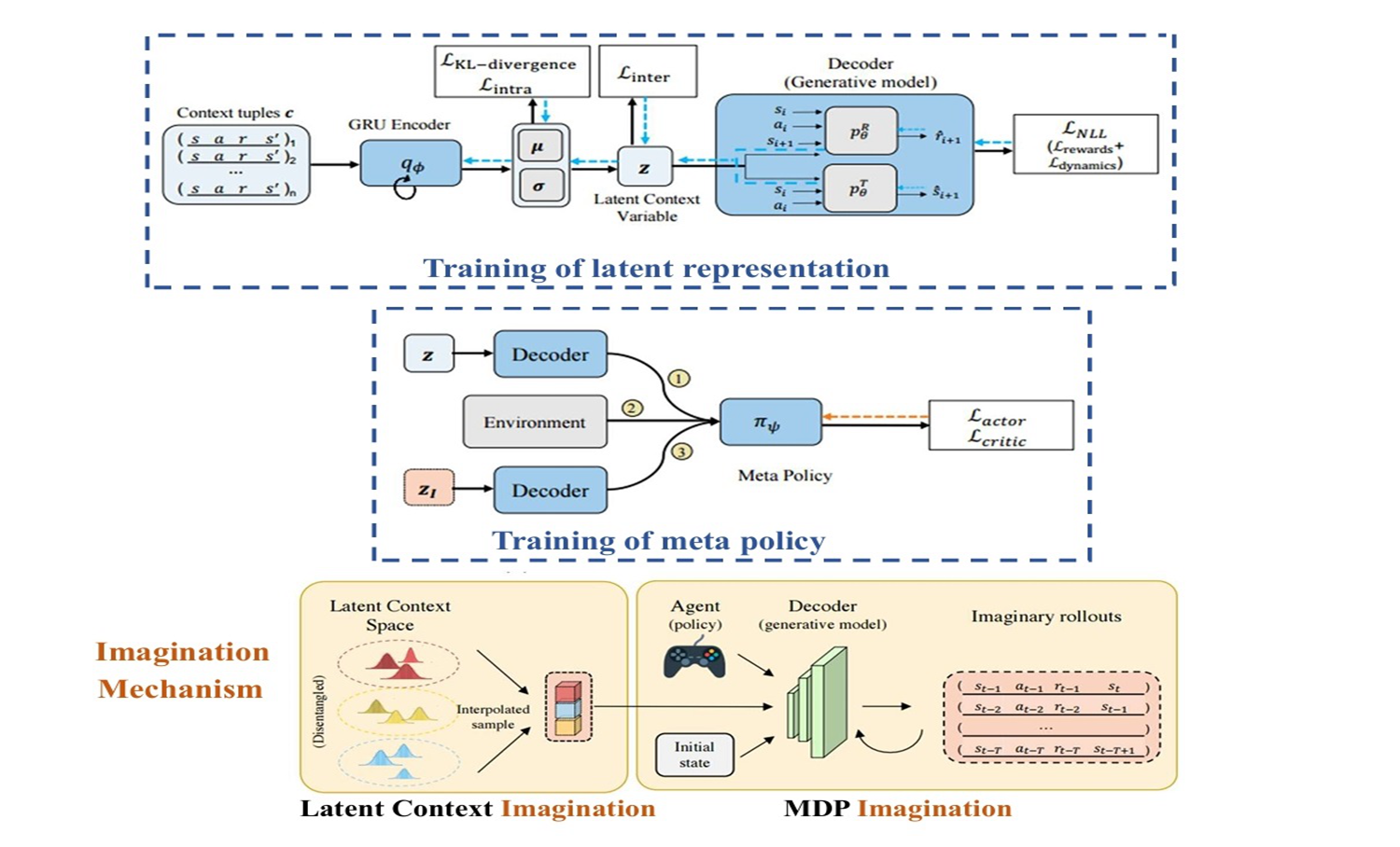
- We introduce MetaDreamer, a novel context-based Meta Reinforcement Learning (RL) algorithm that addresses the high data and task density requirements of existing Meta RL methods. By leveraging meta-imagination through interpolating learned latent context space and MDP-imagination via a generative world model with added physical knowledge, MetaDreamer significantly improves data efficiency and generalization, outperforming current approaches.
Bi-Level Transfer Learning for Lifelong-Intelligent Energy Management of Electric Vehicles
Hao Zhang, Nuo Lei, Wang Peng, Bingbing Li, Shujun Lv, Boli Chen, and Zhi Wang
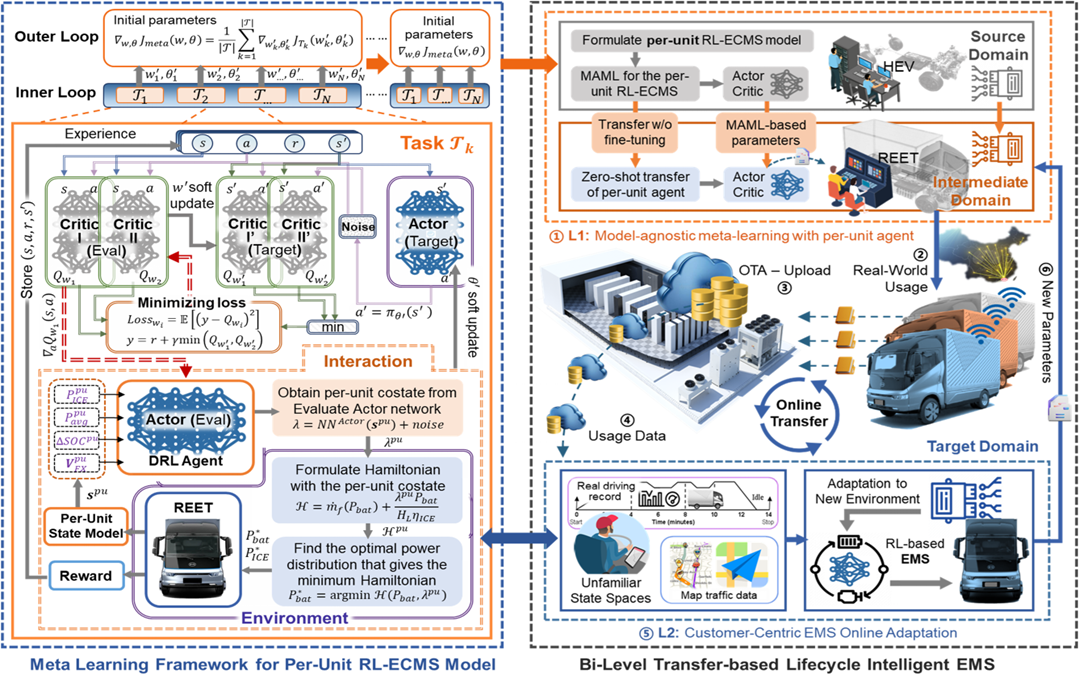
- We proposed a bi-level transfer approach with MAML to realize cross-platform transferable and online-adaptive EMS for REEVs. It contributed to the successful industry deployment of RL methods, implemented in leading automotive company - BYD Auto, significantly enhancing the REEV efficiency.
Generating Socially Acceptable Perturbations for Efficient Evaluation of Autonomous Vehicles
S Zhang, H Peng., S Nageshrao, and H. Eric Tseng
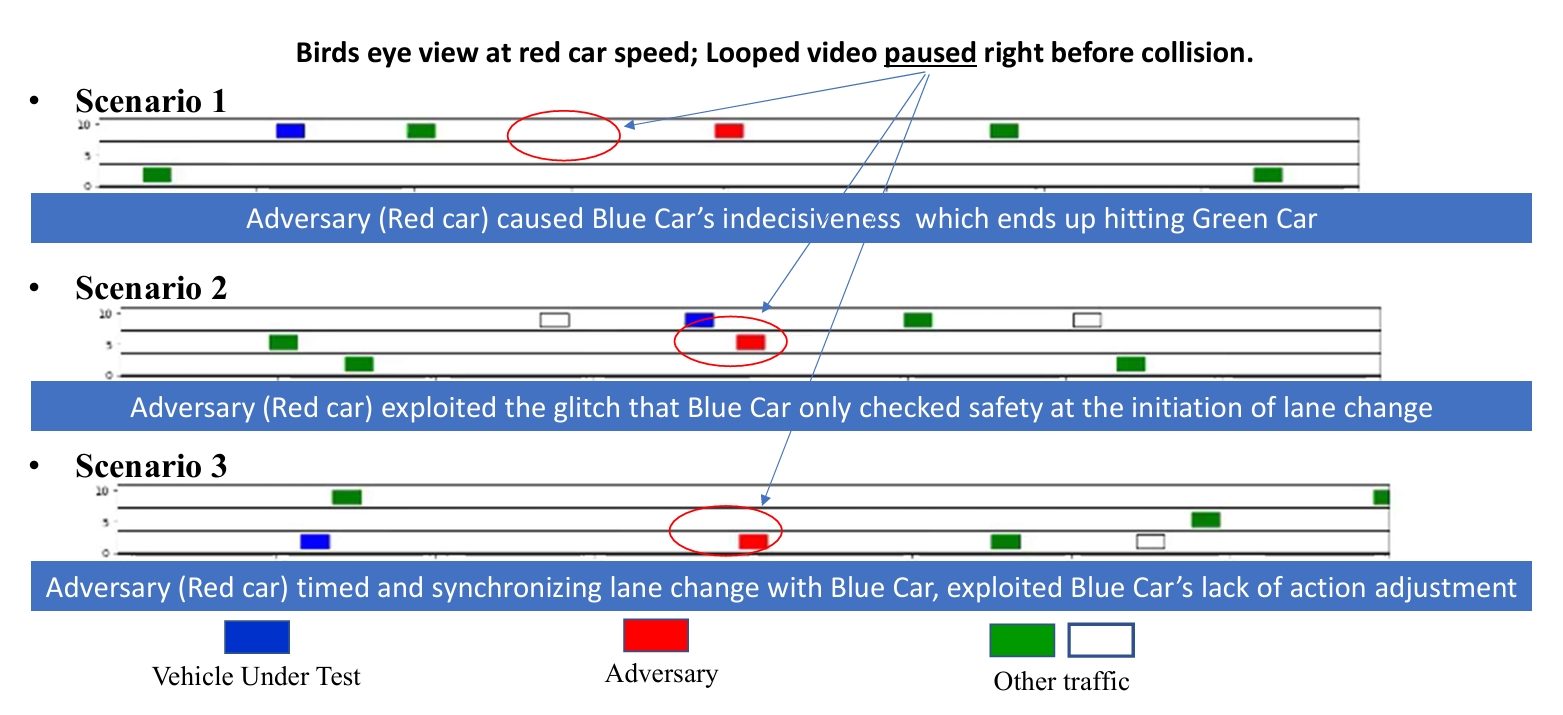
- We introduce a novel approach to evaluate the robustness of deep reinforcement learning-based autonomous vehicle (AV) decision-making. We train a "challenger" agent using deep reinforcement learning to generate Socially Acceptable Perturbations (SAPs), aiming to induce crashes where the AV is primarily at fault, even when the AV's policy performs safely in naturalistic environments.
Lu Wen, Songan Zhang, H. Eric Tseng, Baljeet Singh, Dimitar Filev, and Huei Peng
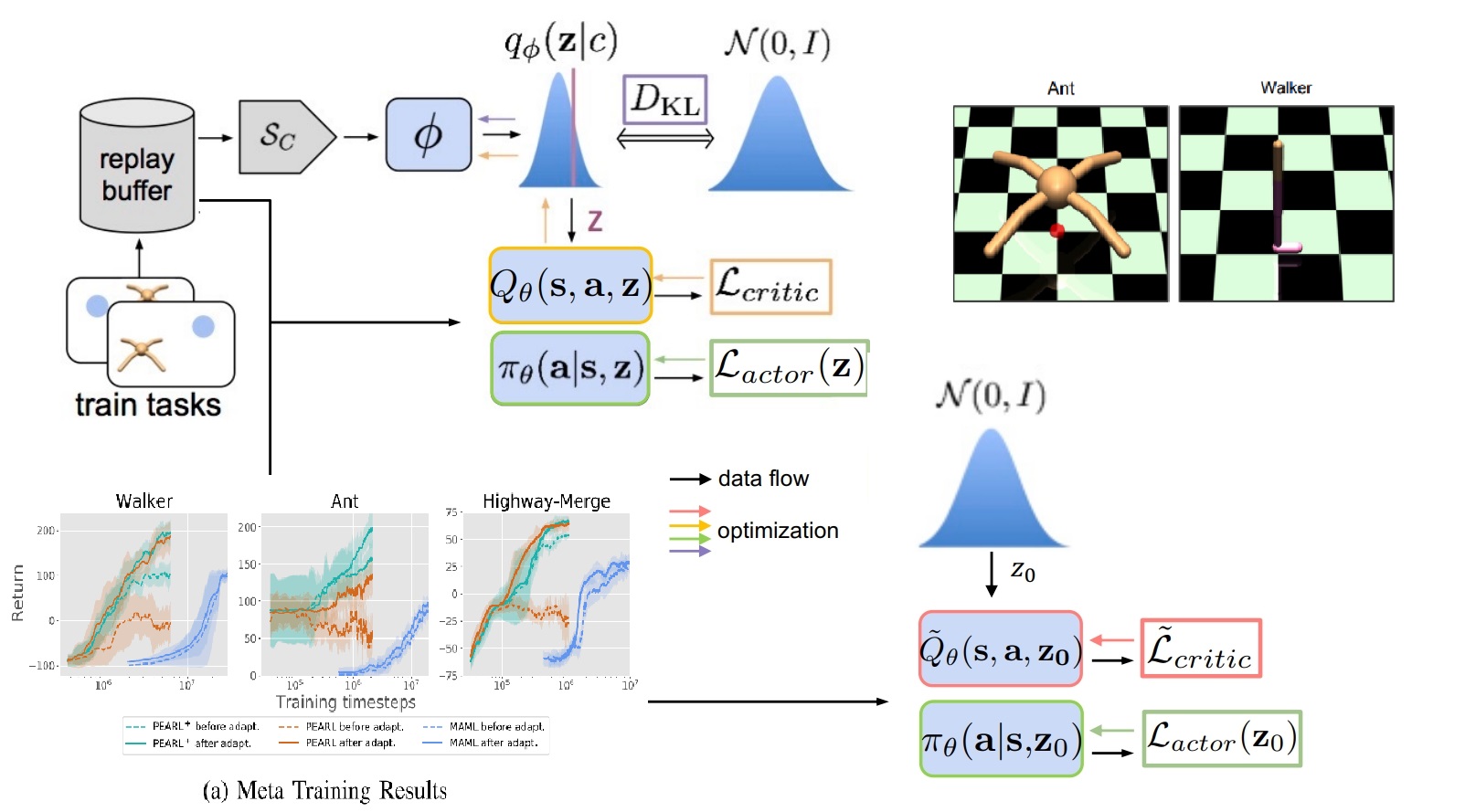
- We developed PEARL+, a Meta-Reinforcement Learning algorithm that significantly enhances safety for autonomous systems. Unlike prior methods, PEARL+ explicitly optimizes for pre-adaptation safety and post-adaptation performance in new tasks, showing improved robustness in critical applications.
Multi-Scale Reinforcement Learning of Dynamic Energy Controller for Connected Electrified Vehicles
Hao Zhang, Nuo Lei, Shengbo Eben Li, Junzhi Zhang, Zhi Wang
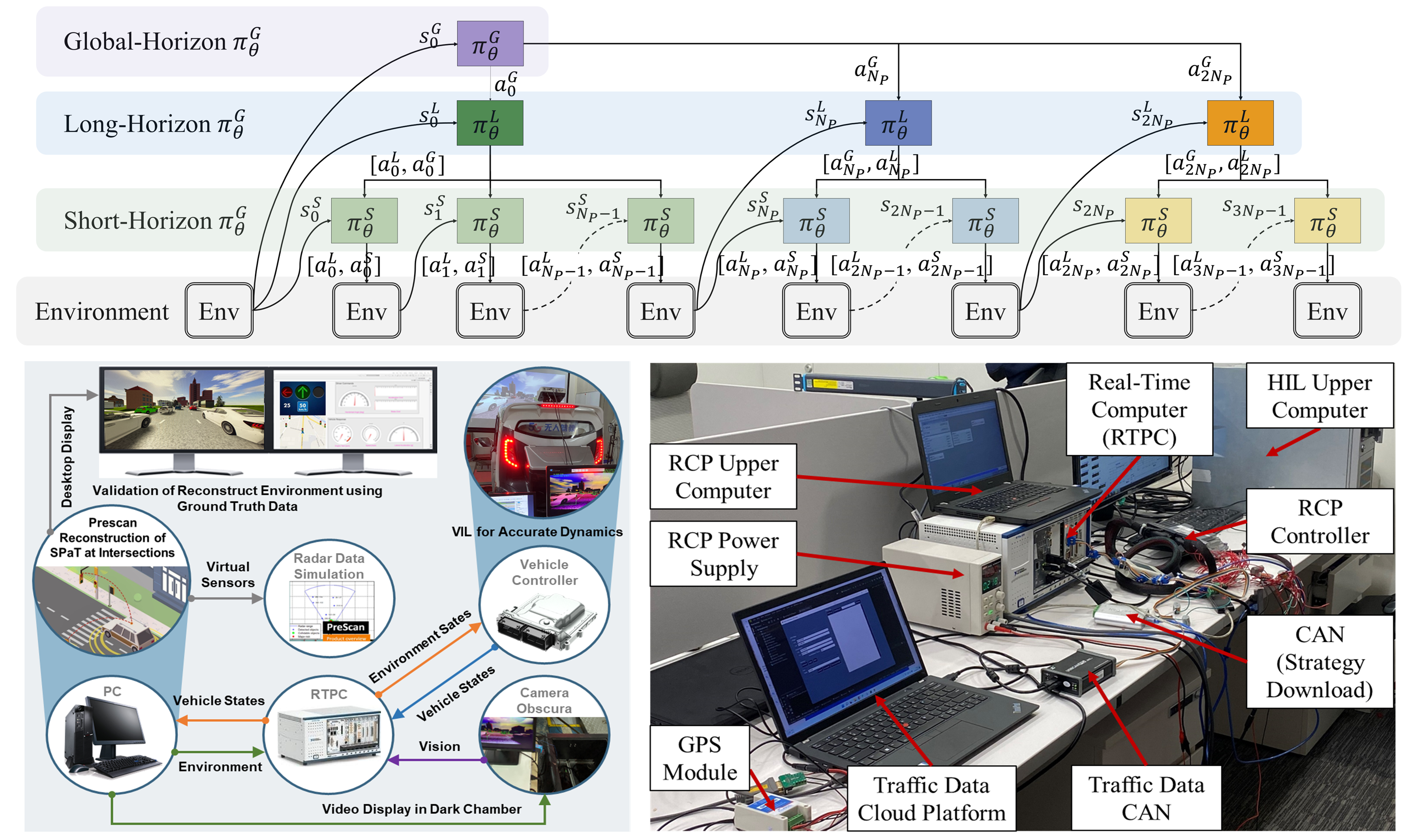
- This study proposes a multi-horizon reinforcement learning (MHRL) featuring a novel state representation and coordinated training of sub-networks across multiple time scales, which greatly improves fuel economy in real-world driving.
Prospective Role of Foundation Models in Advancing Autonomous Vehicles
Jianhua Wu, Bingzhao Gao, Jincheng Gao, Jianhao Yu, HongqingChu, Qiankun Yu, Xun Gong, Yi Chang, H. Eric Tseng, Hong Chen, and Jie Chen
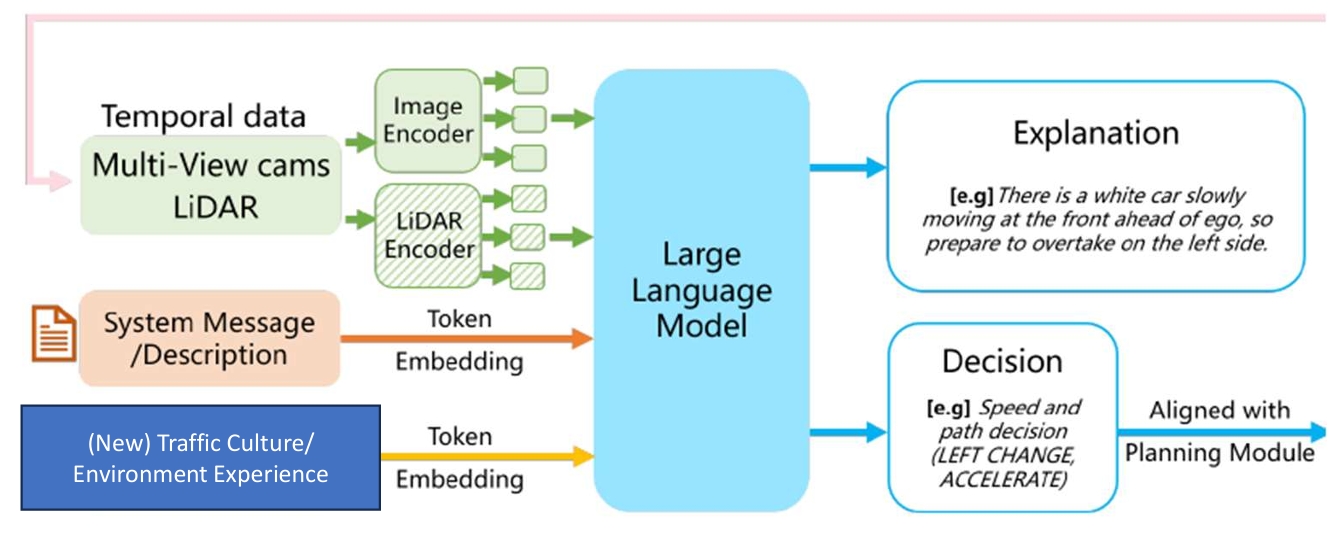
- We present an example of an LLM-driven pipeline for autonomous driving, aiming to advance the application and development of foundation models in the autonomous vehicle domain.
Autonomous Highway Driving using Deep Reinforcement Learning
Subramanya Nageshrao, H. Eric Tseng, and Dimitar Filev
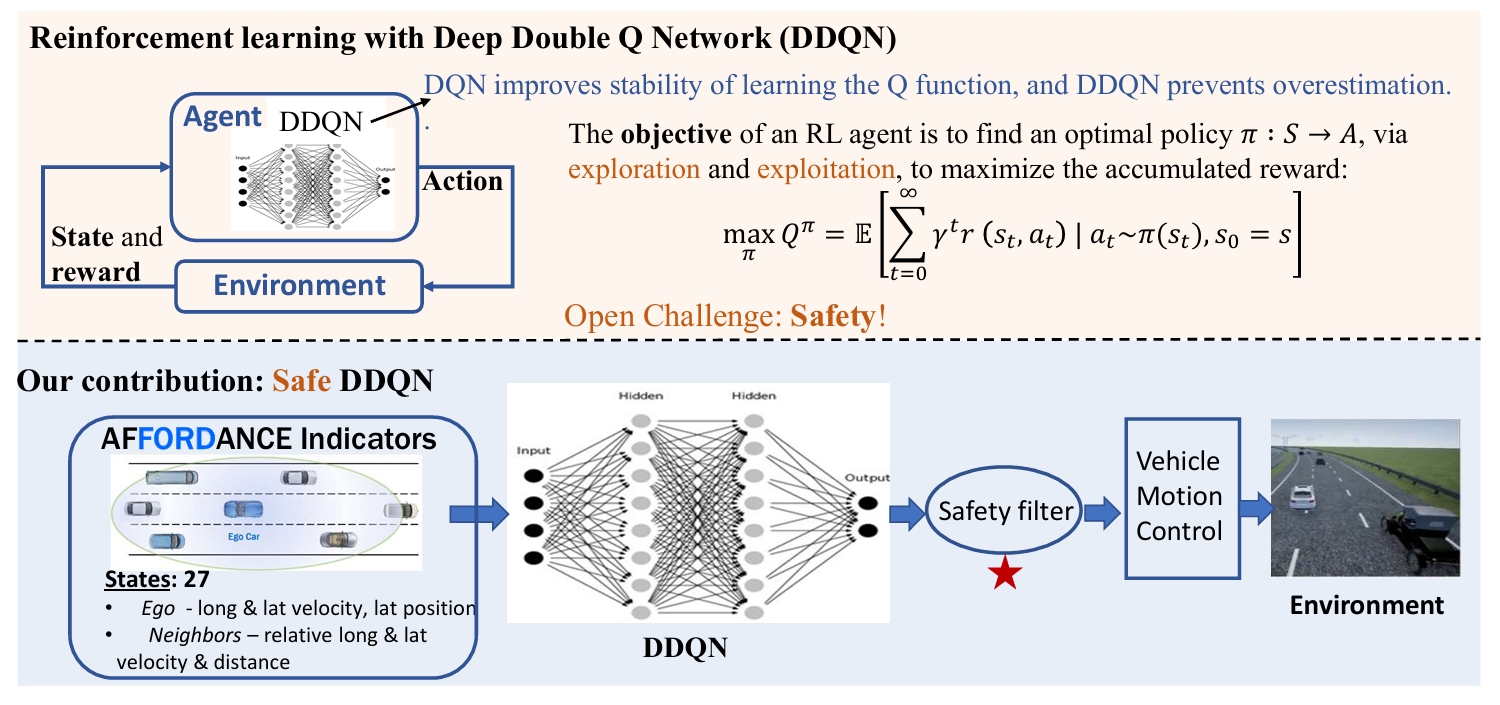
- We proposed a reinforcement learning (RL)-based method where an autonomous vehicle learns to make decisions by interacting directly with simulated traffic, using a deep neural network to select actions for given system states, as demonstrated in highway driving scenarios with varying traffic densities.
Selected Book Chapters
- Tseng, H. E. (2015). Vehicle Dynamics Control. In Encyclopedia of Systems and Control (ISBN: 978-1-4471-5057-2, pp. 1517–1524).
- Hrovat, D., Tseng, H. E., Di Cairano, S., & Annaswamy, A. (2014). Addressing Automotive Industry Needs with Model Predictive Control. In Impact of Control Technology, 2nd Edition (ISBN: 978-0-692-24262-9). IEEE Control Systems Society.
- Geering, H. P. (2010). Linear Parameter-Varying Control of Nonlinear Systems with Applications to Automotive and Aerospace Controls. In The Control Handbook, Second Edition: Control System Applications, Second Edition (pp. 1--1). CRC Press.
- Falcone, P., Borrelli, F., Tseng, E. H., & Hrovat, D. (2010). On low complexity predictive approaches to control of autonomous vehicles. In Automotive Model Predictive Control (Vol. 402, pp. 195–210). Springer London.
Selected Journal Papers
- X. Li, K. Liu, H. E. Tseng, A. Girard and I. Kolmanovsky, "Decision-Making for Autonomous Vehicles With Interaction-Aware Behavioral Prediction and Social-Attention Neural Network," in IEEE Transactions on Control Systems Technology, Early Access.
- S. H. Nair, H. Lee, E. Joa, Y. Wang, H. E. Tseng and F. Borrelli, "Predictive Control for Autonomous Driving With Uncertain, Multimodal Predictions," in IEEE Transactions on Control Systems Technology, Early Access.
- Zhang H, Lei N, Li E S, et al. Multi-scale reinforcement learning of dynamic energy controller for connected electrified vehicles. IEEE Transactions on Intelligent Transportation Systems, 2025, to be published.
- M. Liu, H. Eric Tseng, D. Filev, A. Girard and I. Kolmanovsky, "Game Projection and Robustness for Game-Theoretic Autonomous Driving," in IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 3, pp. 3446-3457, 2025.
- Zhang H, Lei N, Chen B, et al. Bi-level transfer learning for lifelong intelligent energy management of electric vehicles. IEEE Transactions on Intelligent Transportation Systems, 2025, Early Access.
- Lei N, Hao Zhang*, Wang H, et al. Theory-Constrained Neural Network with Modular Interpretability for Fuel Cell Vehicle Modelling. IEEE Trans. on Vehicular Technology, 2025, Early Access.
- L. Wen, E. H. Tseng, H. Peng and S. Zhang, "Dream to Adapt: Meta Reinforcement Learning by Latent Context Imagination and MDP Imagination," in IEEE Robotics and Automation Letters, vol. 9, no. 11, pp. 9701-9708, Nov. 2024.
- Jianhua Wu, Bingzhao Gao, Jincheng Gao, Jianhao Yu, Hongqing Chu, Qiankun Yu, Xun Gong, Yi Chang, H. Eric Tseng, Hong Chen, et al. Prospective Role of Foundation Models in Advancing Autonomous Vehicles. Research. 2024;7:0399.
- Oh, S., Chen, Q., Tseng, H. E., Pandey, G., & Orosz, G. Sharable clothoid-based continuous motion planning for connected automated vehicles. 1–15.
- Zhang H, Lei N, Chen B, et al. Modeling and control system optimization for electrified vehicles: A data-driven approach. Energy, 2024,311:133196.
- Zhang H, Chen B, Lei N, et al. Coupled velocity and energy management optimization of connected hybrid electric vehicles for maximum collective efficiency. Applied Energy, 2024,360:122792.
- Li B, Zhuang W, Zhang H, et al. Traffic-aware ecological cruising control for connected electric vehicle. IEEE Trans. on Transportation Electrification. 2024,10:5225-5240.
- Zhang H, Chen B, Lei N, et al. Integrated thermal and energy management of connected hybrid electric vehicles using deep reinforcement learning. IEEE Trans. on Transportation Electrification, 2024,10:4594-4603.
- Sun H, Li B, Zhang H, et al. Ecological electric vehicle platooning: an adaptive tube-based distributed model predictive control approach. IEEE Trans. on Transportation Electrification, 2024,11:1048-1060.
- Lei N, Zhang H, Li R, et al. Physics-informed data-driven modeling approach for commuting-oriented hybrid powertrain optimization. Energy Conversion and Management, 2024;299:117814.
- Zhang H, Lei N, Chen B, et al. Data-driven predictive energy consumption minimization strategy for connected plug-in hybrid electric vehicles. Energy, 2023,283:128514.
- Yu, H., Tseng, H. E., & Langari, R. A human-like game theory-based controller for automatic lane changing. Transportation Research Part C: Emerging Technologies, 88, 140–158.
- Ranogajec, V., Ivanović, V., Deur, J., & Tseng, H. E. Optimization-based assessment of automatic transmission double-transition shift controls. Control Engineering Practice. 76, 155–166.
- Annaswamy, A. M., Guan, Y., Tseng, H. E., Zhou, H., Phan, T., & Yanakiev, D. Transactive control in smart cities. Proceedings of the IEEE, 106(4), 518–537.
- Sun H, Li B, Zhang H, et al. Ecological electric vehicle platooning: an adaptive tube-based distributed model predictive control approach. IEEE Trans. on Transportation Electrification, 2024,11:1048-1060.
- Deur, J., Milutinović, M., Ivanović, V., & Tseng, H. E. (2016). Modeling of a dry dual clutch utilizing a lever-based electromechanical actuator. Journal of Dynamic Systems, Measurement, and Control, 138(9), 091012.
Selected Conference Papers
- L. Wen, S. Zhang, H. E. Tseng, B. Singh, D. Filev and H. Peng, "Improved Robustness and Safety for Pre-Adaptation of Meta Reinforcement Learning with Prior Regularization," IEEE IROS, 2022.
- S. Zhang, L. Wen, H. Peng, and H. E. Tseng. "Quick learner automated vehicle adapting its roadmanship to varying traffic cultures with meta reinforcement learning." In IEEE ITSC, 2021.
- Zhang, S., Peng, H., Nageshrao, S., & Eric Tseng, H. (2020). Generating Socially Acceptable Perturbations for Efficient Evaluation of Autonomous Vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (2020 CVPRW)
- Nageshrao, S., Tseng, H. E., & Filev, D. Autonomous highway driving using deep reinforcement learning. In 2019 IEEE SMC
- Zhang, S., Peng, H., Zhao, D., & Tseng, H. E.. Accelerated evaluation of autonomous vehicles in the lane change scenario based on subset simulation technique. 2018 21st International Conference on Intelligent Transportation Systems (ITSC), 3935–3940.
- Zhang, Q., Filev, D., Tseng, H. E., Szwabowski, S., & Langari, R.. Addressing mandatory lane change problem with game theoretic model predictive control and fuzzy Markov chain. 2018 Annual American Control Conference (ACC), 4764–4771.
- Lee, S., & Tseng, H. E. (2018). Trajectory planning with shadow trolleys for an autonomous vehicle on bending roads and switchbacks. 2018 IEEE Intelligent Vehicles Symposium (IV), 484–489.
- Liu, C., Lee, S., Varnhagen, S., & Tseng, H. E.. Path planning for autonomous vehicles using model predictive control. 2017 IEEE Intelligent Vehicles Symposium (IV), 174–179.
- Bujarbaruah, M., Ercan, Z., Ivanovic, V., Tseng, H. E., & Borrelli, F.. Torque-based lane change assistance with active front steering. 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), 1–6.
- Xu, L., Tseng, H. E., & Hrovat, D.. Hybrid model predictive control of active suspension with travel limits and nonlinear tire contact force. 2016 American Control Conference (ACC), 2415–2420.
- Velazquez Alcantar, J., Assadian, F., Kuang, M., & Tseng, E.. Optimal longitudinal slip ratio allocation and control of a hybrid electric vehicle with eawd capabilities. Dynamic Systems and Control Conference, 50701, V002T30A002.
- Ercan, Z., Carvalho, A., Lefevre, S., Gokasan, M., Tseng, H. E., & Borrelli, F.. Torque-based steering assistance for collision avoidance during lane changes. Advanced Vehicle Control: Proceedings of the 13th International Symposium on Advanced Vehicle Control.
- Gao, Y., Gray, A., Carvalho, A., Tseng, H. E., & Borrelli, F.. Robust nonlinear predictive control for semiautonomous ground vehicles. 2014 American Control Conference, 4913–4918.
- Turri, V., Carvalho, A., Tseng, H. E., Johansson, K. H., & Borrelli, F.. Linear model predictive control for lane keeping and obstacle avoidance on low curvature roads. 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), 378–383.
- Lin, T., Tseng, E., & Borrelli, F.. Modeling driver behavior during complex maneuvers. 2013 American Control Conference, 6448–6453.
---------------------------------------------------------------------------------------------------------------
Selected Patents
- Tseng, E. H., Xu, L., Simmons, K., & Blue, D. (2019). Autonomous parking of vehicles in perpendicular parking spots.
- Xu, L., Simmons, K., Zhang, C., & Tseng, E. H. (2019). Hitch assist system and method.
- Zhang, Y., Tseng, E. H., Lakehal-ayat, M., & Pilutti, T. E. (2019). Hitch assist system with hitch coupler identification feature and hitch coupler height estimation.
- Tseng, E. H., Xu, L., Hrovat, D. D., Deur, J., & Coric, M. (2018). Vehicle handling dynamics control using fully active suspension.
- Hippalgaonkar, R., Kucharski, J. F., Fujii, Y., Pietron, G. M., Meyer, J., & Tseng, E. H. (2018). Transmission input torque management.
- Lu, J., Hrovat, D. D., & Tseng, H. E. (2017). Off-road autonomous driving.
- Xu, L., & Tseng, E. H. (2017). Hill parking aid.
- Fodor, M. G., & Tseng, H. E. (2017). Output torque control method.
- Attard, C., Elwart, S., Greenberg, J. A., Johri, R., Kochhar, D. S., Rhode, D. S., Shutko, J., & Tseng, E. H. (2016). Modified autonomous vehicle settings.
- Attard, C., Elwart, S., Greenberg, J. A., Johri, R., Joyce, J. P., Kochhar, D. S., Rhode, D. S., Shutko, J., & Tseng, H. E. (2016). Fault handling in an autonomous vehicle.
- Tseng, E. H., Hrovat, D., Lu, J., McConnell, M., Dehmel, M., Seemann, M., & Owens, F. V. (2016). Suspension control system to facilitate wheel motions during parking.
- Fodor, M. G., Tseng, H. E., Riedle, B. D., & Hrovat, D. D. (2016). Vehicle adapted to control clutch torque based on relative speed data.
- Attard, C., Elwart, S., Greenberg, J. A., Johri, R., Joyce, J. P., Kochhar, D. S., Rhode, D. S., Shutko, J., & Tseng, E. H. (2015). Fault Handling in an autonomous vehicle.
- Tseng, H. E., Teslak, C. J., Riedle, B. D., Doering, J. A., & Pallett, T. J. (2015). Method of controlling automatic transmission coasting downshift.
- Tseng, E. H., Hrovat, D., Lu, J., McConnell, M., Dehmel, M., Seemann, M., & Owens, F. V. (2014). Suspension control system to facilitate wheel motions during parking.
- Tseng, H. E., Fodor, M., & Hrovat, D. (2014). Adaptive traction control system.
- Tseng, H. E., Yanakiev, D., Hrovat, D. D., & Jankovic, M. J. (2012). Spark timing adjustment based on vehicle acceleration.
- Tseng, H. E., Fodor, M. G., Teslak, C. J., Riedle, B. D., & Davidson, E. A. (2011). Vehicle Launch Startup Clutch Protection on a Grade.
More publications and patents can be found on Prof. Tseng's Google Scholar homepage.